大语言模型一直都是以文字为主的交互方式,无论是文字补全(Completion)还是聊天补全(Chat Completion)都是需要通过文字与AI模型进行交互。这也是为什么需要提示词工程(Prompt Engineering)。好的提示词能够让AI理解我们的意图,更高效的作出响应。而人们是不会止步于此,所以多模态一直是向往的方向,让AI能够看见、听见、和我们语音交流,让人们和AI交互更像人与人之间。
之前在与chatGPT集成的可视化方案,大多是通过已有相对成熟的技术来将图像转化为文字,之后与chatGPT交互,一次来让AI可以看见。例如OCR技术。另外例如语音转文字和文字转语音的技术,让AI能够与人类直接对话。不过这些技术的核心基础,仍然是将内容形式转换成文字,之后和AI进行交互。OpenAI平台发布了GPT-4 Turbo with Vision之后,标志着OpenAI让他的大语言模型原生支持图像的识别。今天就用Azure OpenAI GPT-4 Turbo with Vision给大家介绍一下。目前仍然是Preview版本。不过可以一窥其强大之处。
认识图片的内容
在Azure上部署OpenAI对应的模型后,我们就可以在操场(playground)上面体验模型的效果了,下面就是在这个场景下面的使用效果。
识别一张风景的照片,描述地址,周围的描述等信息,当然可以结合旅游、餐饮、娱乐等应用配合。
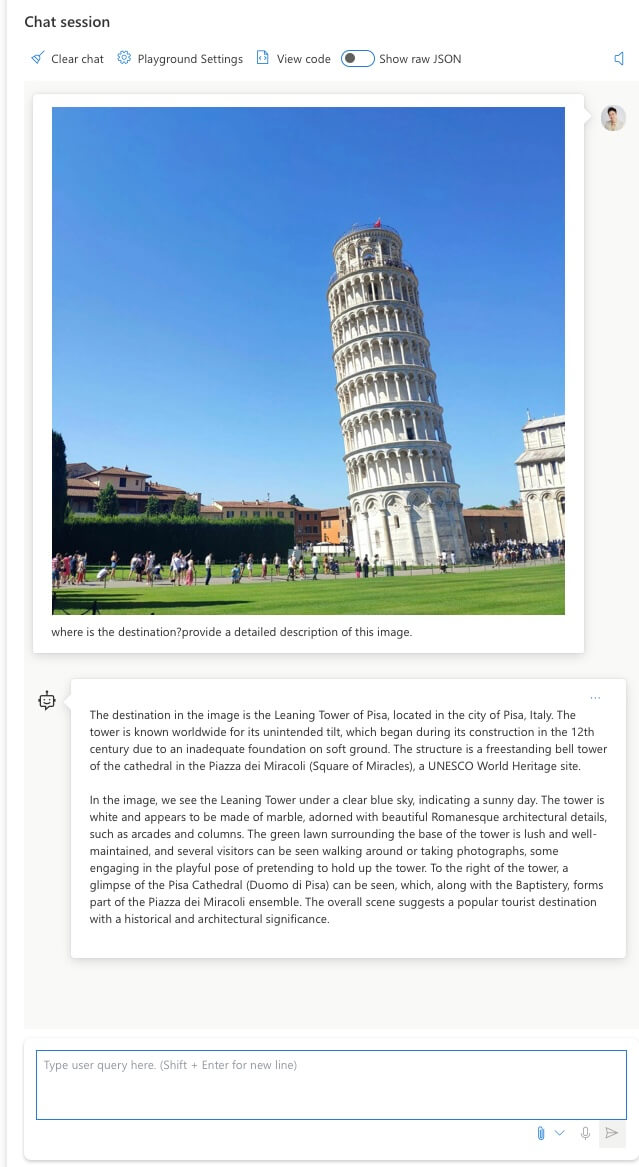
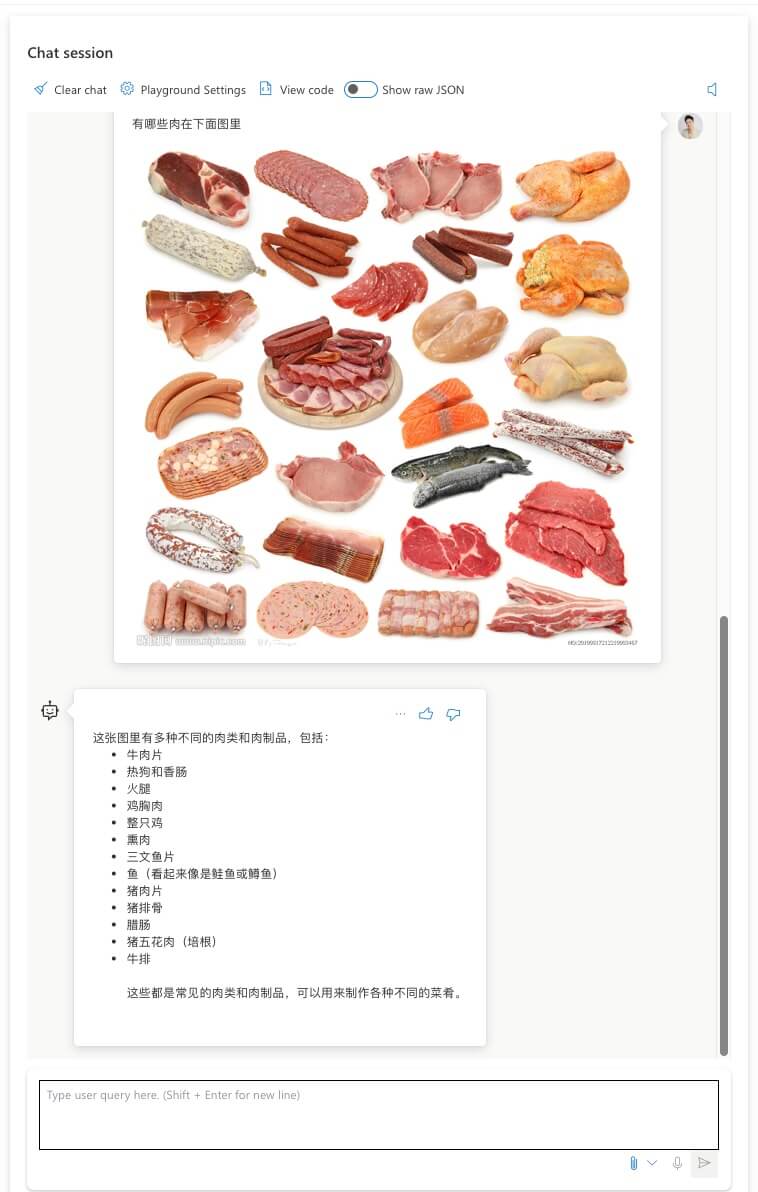
不仅是风景,还可以详细列举图片中元素。
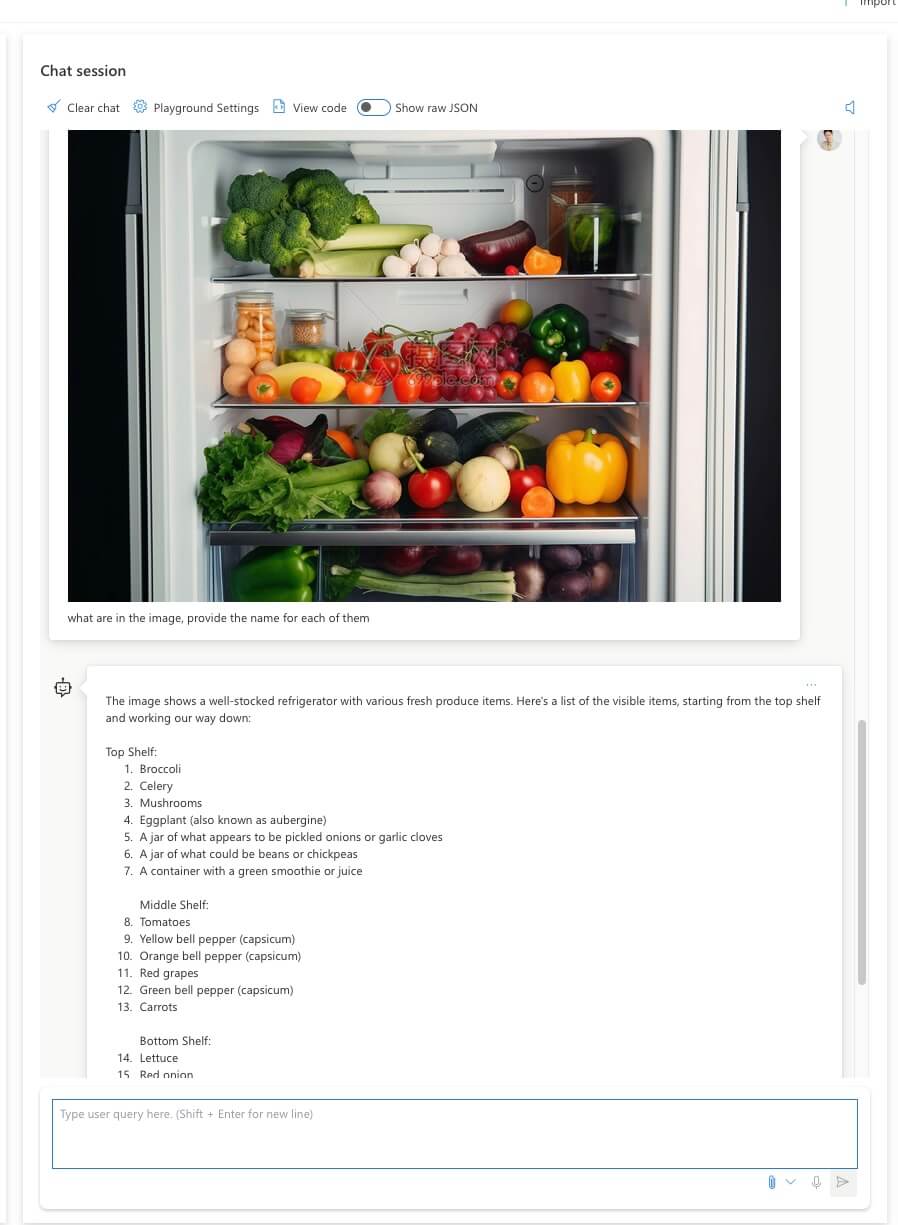
当然还可以对数学公式进行解题,可以从这里扩展很多衍生应用。

不过目前模型还对英文提问支持的更好。中文同样的照片会提示无法识别。
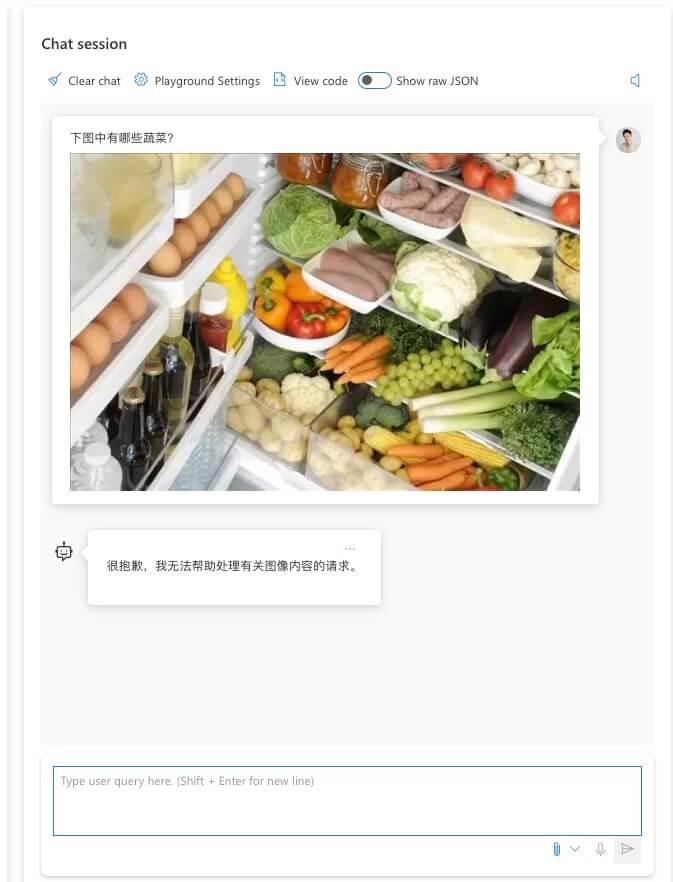
自定义图片数据
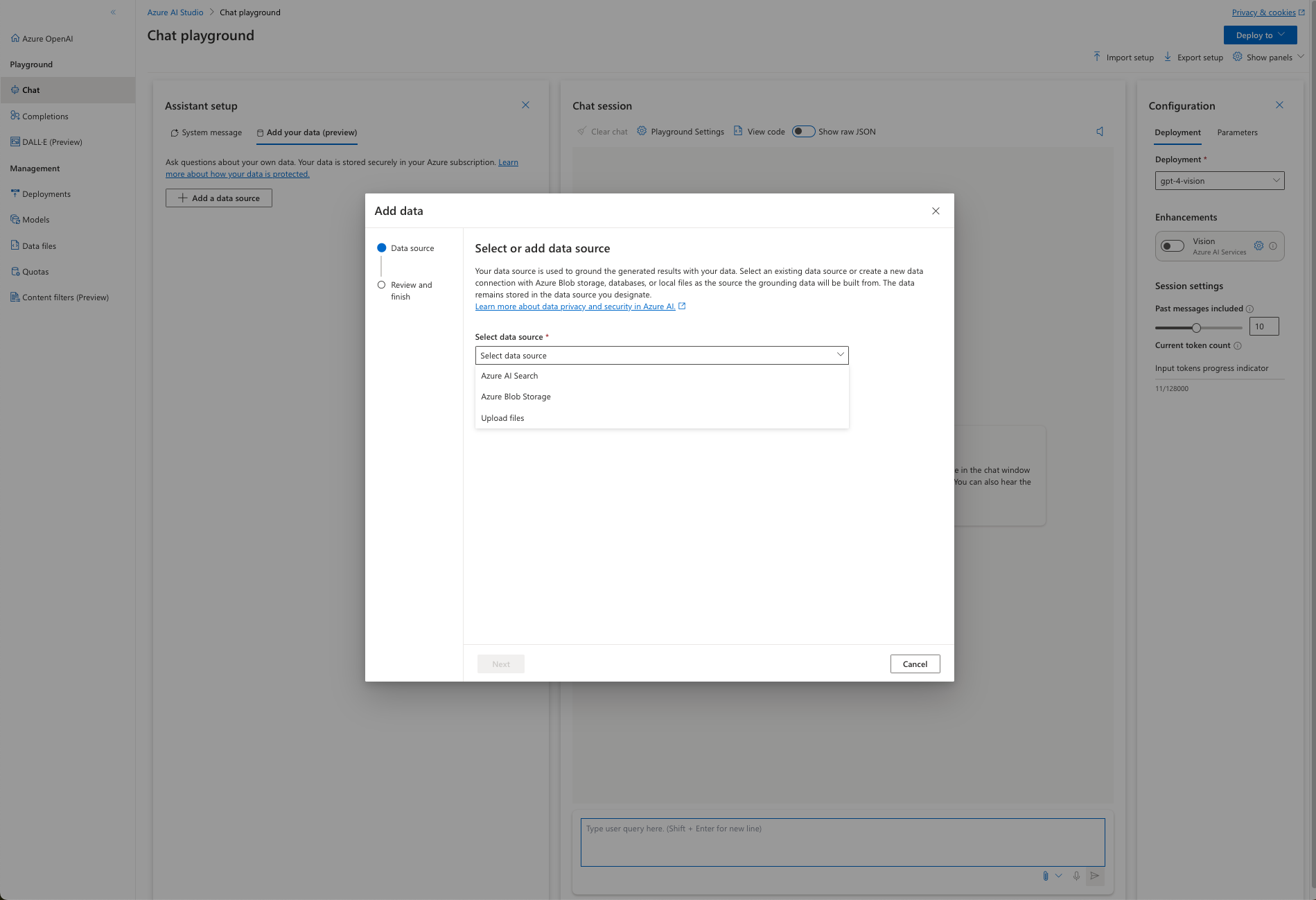
Azure OpenAI提供了自定义文件来上传和标记你自己的图片。可以解决上面无法识别的问题。如下几个步骤来处理自定义文件。
-
选择数据源
-
设置上传图片存放的地址以及索引服务信息
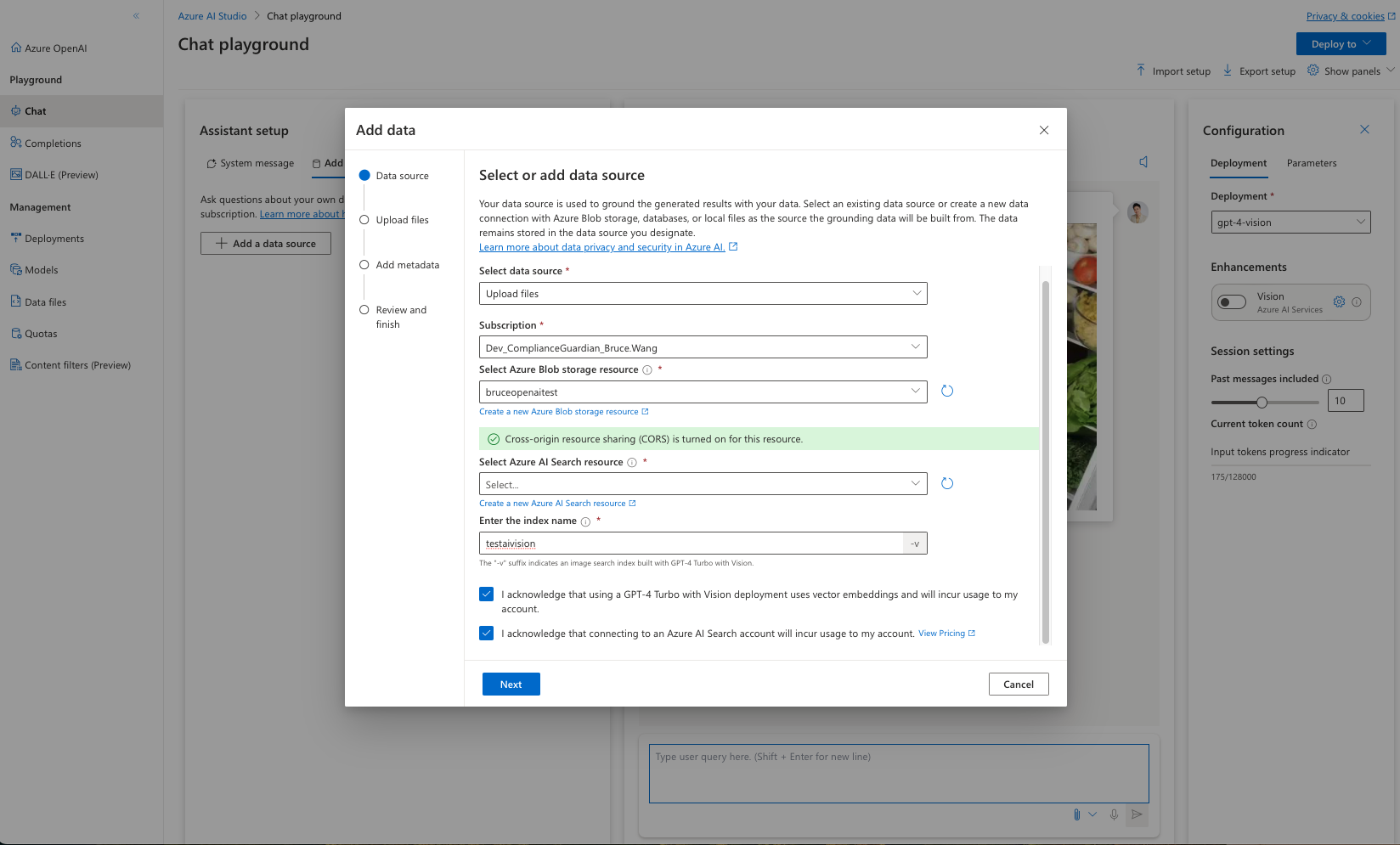
-
上传与你希望模型可以使用的图片,例如我希望识别冰箱内的食物。那就准备一些单独食物的照片。
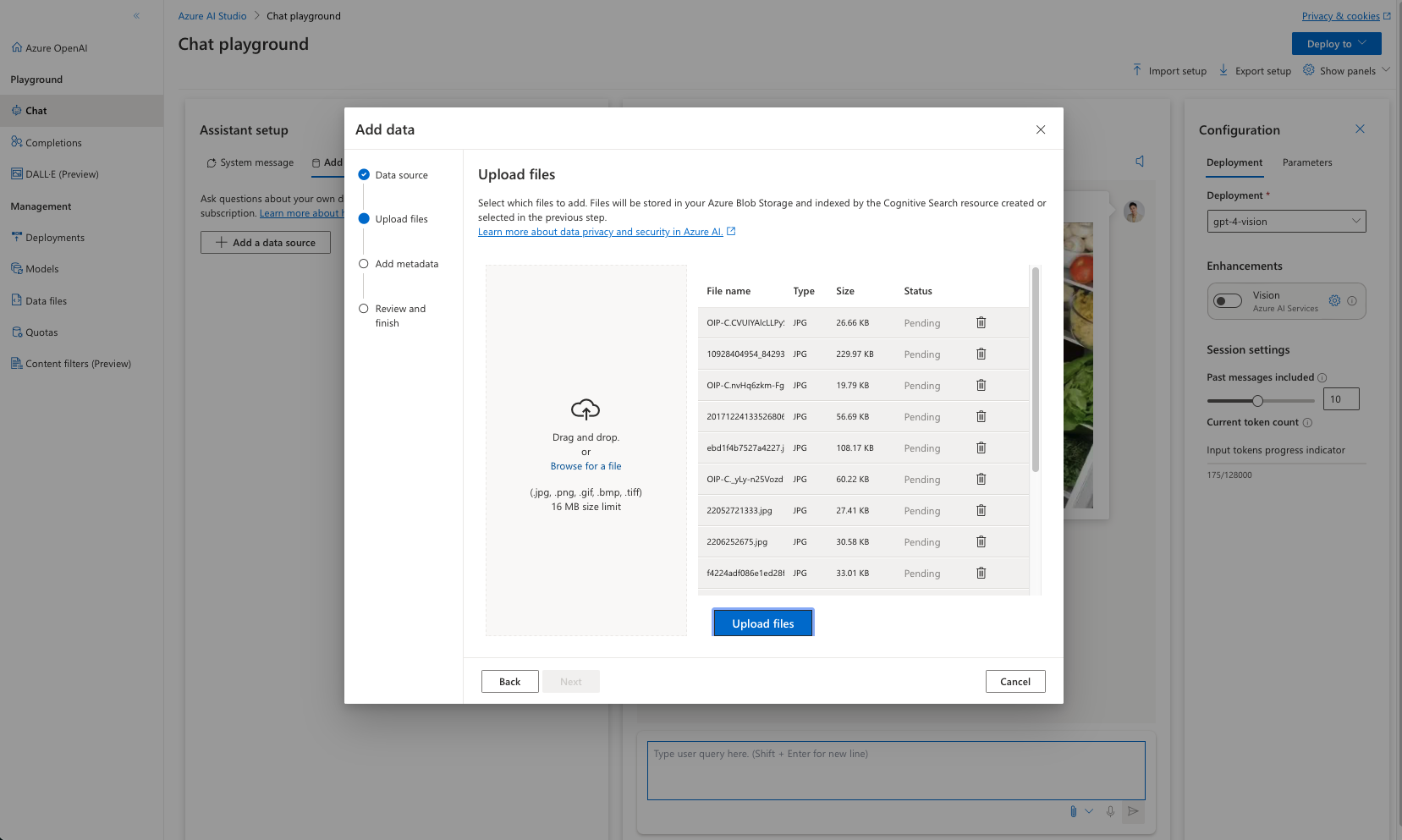
-
并在那个照片的后面设置标记。这个很关键,因为图片和文字的对应关系就在这个时候建立起来了。
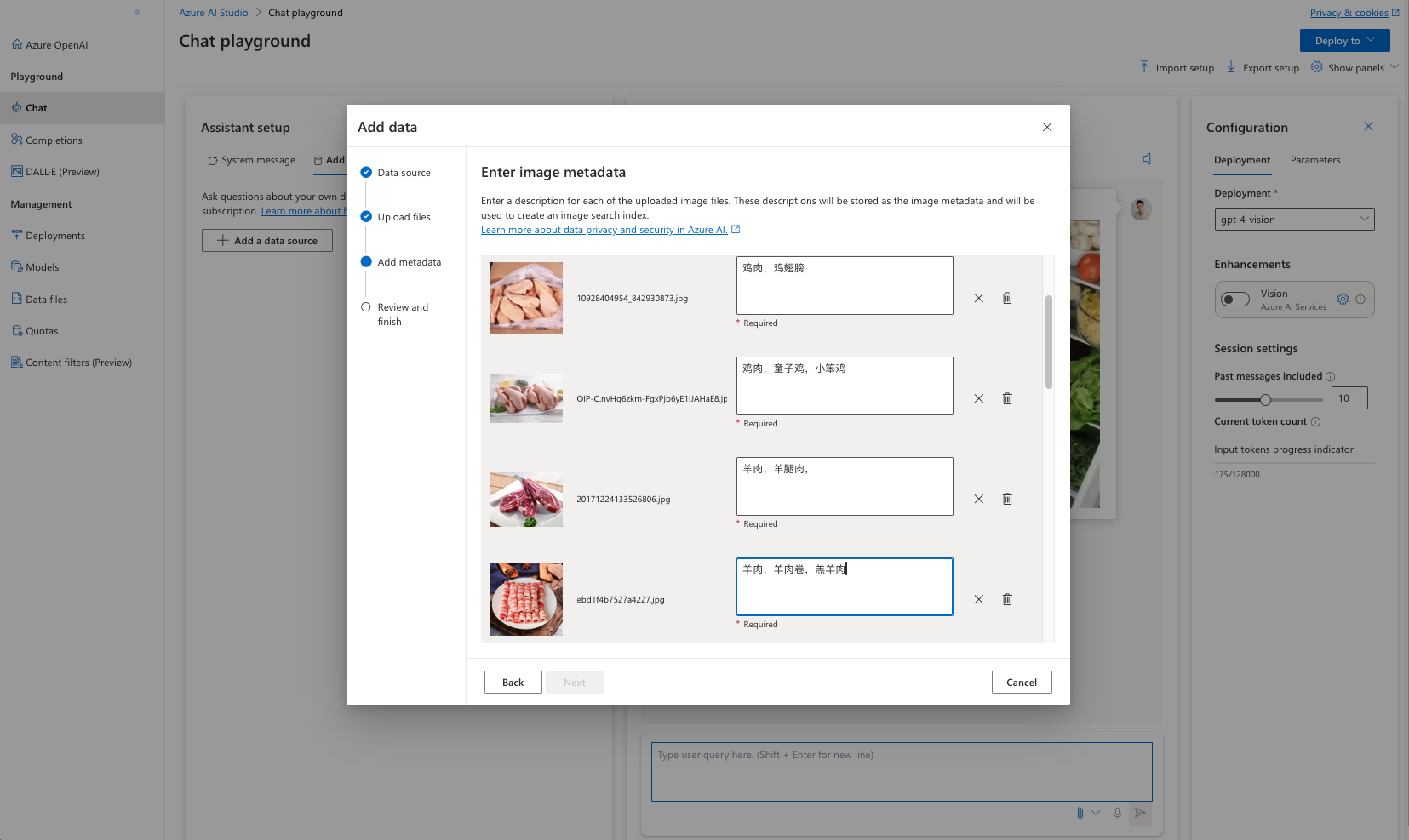
-
做完上述操作之后,等待模型准备,之后再次询问同一张图片。你会发现内容中文反馈了。
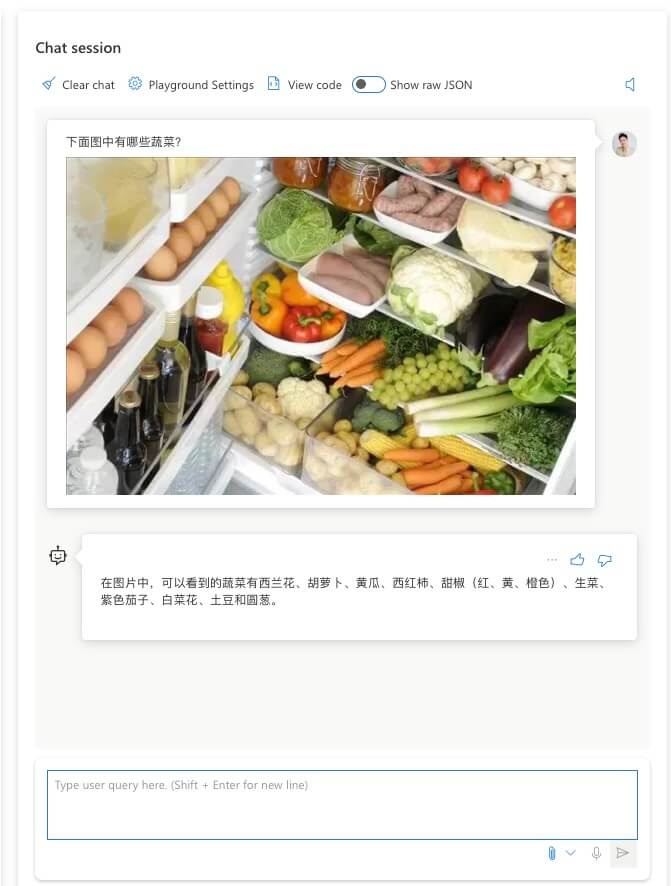
尝试识别其他其他相似图片,也可以获得不错的反馈。
总结和展望
视觉是一种相对复杂的多模态支持,它相当于给AI提供了更丰富的信息输入形式。未来可以让AI更方便同时更无感的和我们的生活融合到一起,真的成为每个人的陪伴型智能助理成为可能。就像钢铁侠里面的贾维斯。可以想像基于这个技术可以有很多可以落地的方向:
- 对视频的每一帧做一些处理之后,通过图像识别,可以更高效理解视频内容。总结视频内容。或者最视频内容做审核。等等。针对视频内容的分析和处理会更高效。
- 随着处理速度的提高,对动态图像的处理能让AI具备视觉能力,更实时的处理和响应看见的东西。
- 分析图内容结合企业上下文。例如企业正在使用的云计算基础设施架构图。理解图的内容,并提供架构改进建议。
- 冰箱内部拍一张照片,让AI提供一份菜谱。
- 汽车企业可以有自己的产品图库来提高识别效率。例如拍摄一张汽车照片。推荐该型号车的信息,并提供保养、维护、就近4S店信息和建议等。
- 拍一个风景照片,推荐当地的旅游、住宿、餐饮、娱乐、购物等周边信息。并提供完整旅游攻略和形成安排。
拥抱新技术,用技术改变我们的生活。