第一次接触 Foundry IQ 时,很多人会把它误认为 Azure AI Search 的新名字,或者把它理解成“给传统 RAG 套了一层新 UI”。
但真正在项目里配置起来,最容易混淆的往往是这几个问题:
- Foundry IQ 与 Azure AI Search 到底是什么关系?
- 检索这件事为什么还需要 LLM 参与?
- 它和传统 RAG 的差别,究竟只是产品包装,还是能力边界真的变了?
这篇文章不做产品功能罗列,而是专门拆这几个最容易混淆的点,帮助你判断 Foundry IQ 适合解决什么问题,又不适合解决什么问题。
先澄清命名:两个入口是不是同一个 Foundry IQ?
它们指向同一套 Foundry IQ 知识库能力,但属于不同的管理界面。
- Azure 门户中的 Foundry IQ(Azure AI Search) 更偏底层资源管理,包括 Search Service、索引、索引器、Knowledge Source、Knowledge Base 和 agentic retrieval。
- Microsoft Foundry 项目中的 Knowledge(Foundry IQ) 偏 Agent 开发体验,用于创建、配置和连接 Knowledge Base。
两边最终操作的 Knowledge Base 和 Knowledge Source 都托管在选定的 Azure AI Search Resource 中。如果 Search Endpoint(例如 https://my-search-service.search.windows.net)和 Knowledge Base 名称相同,看到的就是同一个底层知识库。
部分产品与定价页面会显示 Foundry IQ(Azure AI Search),但这不等于所有 Azure AI Search 技术名称都已被替换。至少从当前官方技术文档来看,Azure AI Search 仍然是 Foundry IQ 的底层索引与检索基础设施;Index、Indexer、Skillset、Vector Search 和 Search API 也继续沿用 Azure AI Search 名称。
Microsoft Foundry
└─ Knowledge(Foundry IQ)
└─ Project Connection
└─ Azure AI Search Resource
├─ Knowledge Base / Knowledge Sources
├─ Index / Indexer / Vector Search
└─ Agentic Retrieval
一句话概括:Azure AI Search 负责“搜”,Foundry IQ 负责把搜索组织成可供 Agent 复用的知识服务。
换句话说,它们不是两套彼此替代的产品,而是同一条能力链路上分工不同的两个层次。
Knowledge Base 为什么也需要 LLM?
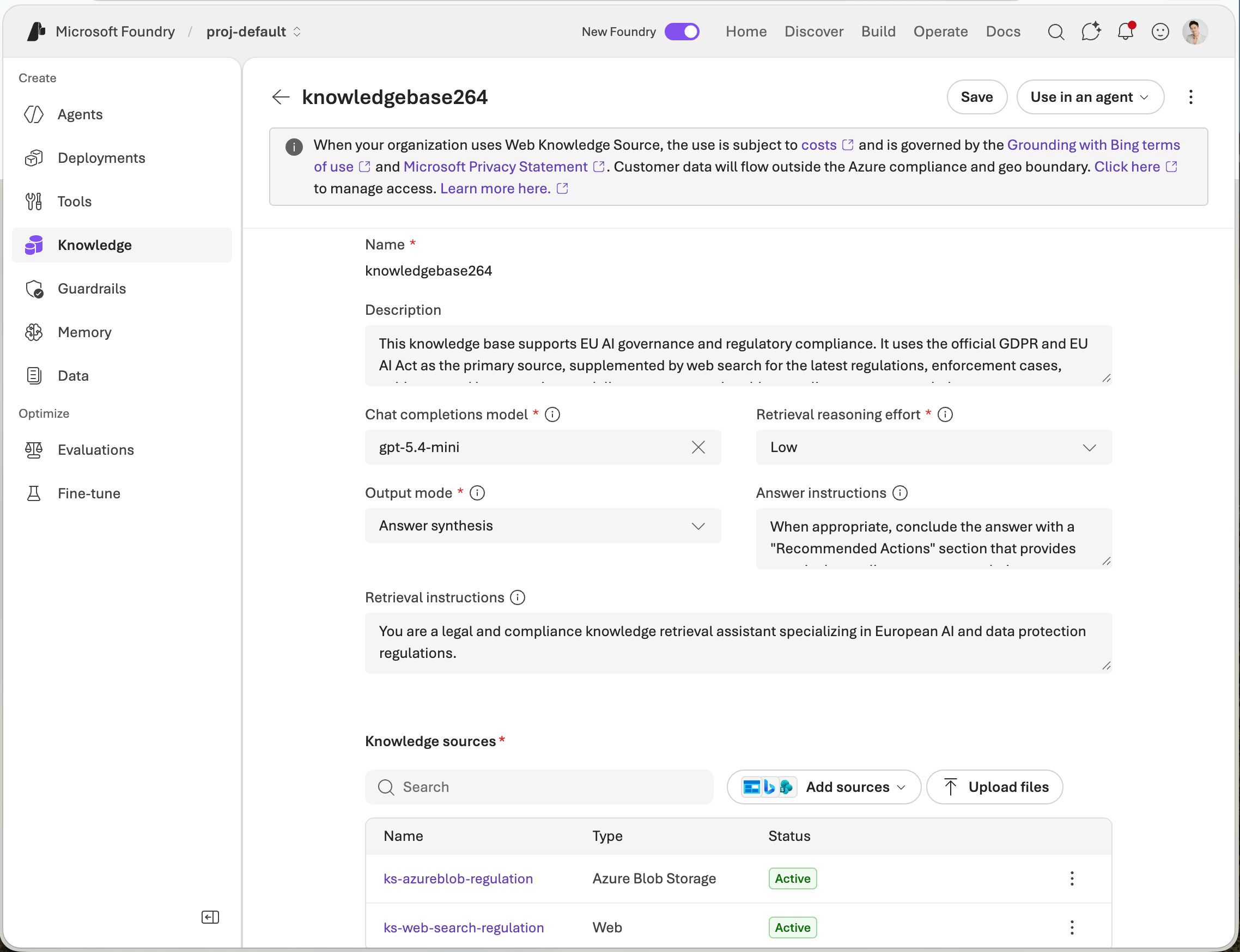
截图中的 Chat Completions Model 属于 Knowledge Base 的检索管线。它不是生成向量的 Embedding Model,也不一定是 Agent 的主模型。按本文写作时的官方文档口径,用于查询规划(query planning)的 LLM 主要限于 gpt-4o、gpt-4.1 和 gpt-5 系列的 Azure OpenAI 部署,后续支持范围仍可能调整。它主要承担三项工作:
- 查询规划:结合用户问题和对话历史,把复合问题拆成更聚焦的子查询。
- 查询与知识源规划:判断应该查询哪些来源并生成子查询;随后由 Azure AI Search 执行关键词、向量或混合检索与语义重排。
- 可选的答案合成:当 Output Mode 为
Answer synthesis时,将证据合成为带引用的答案;使用Extracted data时,则把检索内容和来源交给 Agent 生成最终回答。
Retrieval reasoning effort 控制 LLM 介入检索的程度,并直接决定可用资源上限:
| 模式 | 核心行为 | 限额(来自官方 FAQ) | 建议 |
|---|---|---|---|
Minimal |
不做 LLM 查询规划,直接搜索 | 最多 10 个 knowledge sources;无 LLM、无答案合成 | 最低成本和延迟;仅支持提取式结果,不支持 Web 知识源 |
Low |
一轮查询规划和知识源选择,默认模式 | 最多 3 个 sources / 3 个子查询;答案合成预算 5,000 tokens | 大多数场景的起点 |
Medium |
首轮结果不足时可修订查询并再检索一次 | 最多 5 个 sources / 5 个子查询;答案合成预算 10,000 tokens | 复杂、跨来源、重视完整性的任务 |
推理强度越高,通常检索覆盖更好,但延迟与 token 成本也会上升。实际限额仍应以当时的官方 limits 与 FAQ 为准。
另外,Web 等远程 Knowledge Source 必须启用 Answer synthesis 才能返回结果,因此 Minimal 模式(无答案合成)天然不支持 Web 源。
这里还要区分两个模型角色:Knowledge Base 的 LLM 优化“如何找到证据”,Agent 的 LLM 负责“如何完成任务”。 两者可以使用相同部署,也可以不同。对于还要调用其他工具并统一组织答案的 Foundry Agent,官方建议优先使用 Extracted data,把原始证据和引用交给 Agent 推理,避免知识库和 Agent 重复生成答案;只有在检索结果直接面向终端用户、不需要 Agent 二次加工的场景,才更适合使用 Answer synthesis。
如果把这段话说得更直白一点:这里的 LLM 不是负责“回答问题”,而是负责“把问题问对、把证据找对”。
为什么 Blob Knowledge Source 也要配置模型?
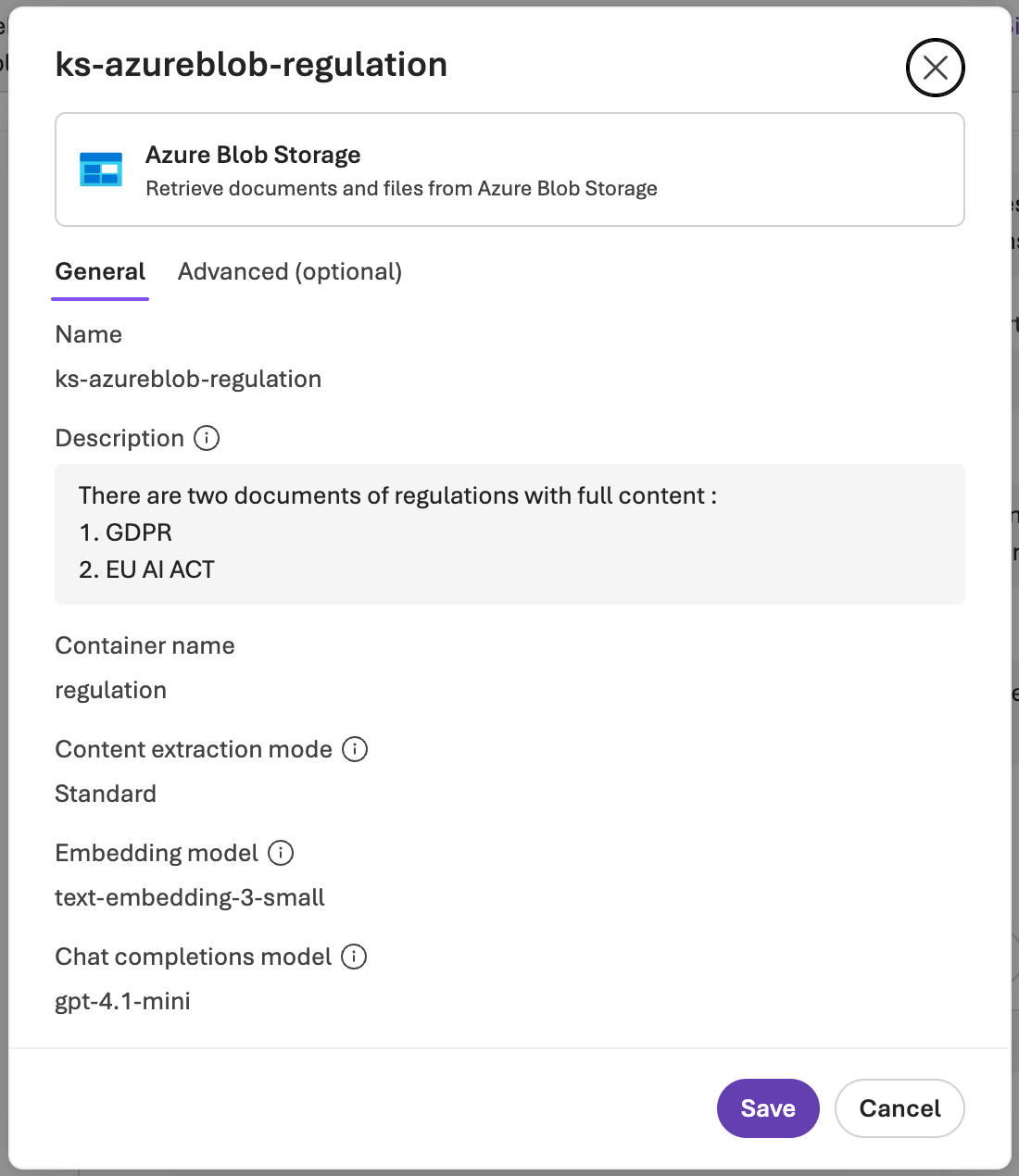
先说结论:Blob 页面配置模型,是为了在摄取阶段把原始文档变成更容易检索的内容;Knowledge Base 页面配置模型,则是为了在检索阶段理解问题并编排检索。
两处虽然都出现 Chat Completions Model,但它们工作在 RAG 的不同阶段:
| 模型 | 运行阶段 | 作用 |
|---|---|---|
| Blob 的 Chat Model | 文档摄取、建索引或刷新时 | 生成式内容提取,尤其是把图片、图表等视觉内容描述成可检索文本 |
| Blob 的 Embedding Model | 建索引及向量查询时 | 将文档分块和用户查询转换成向量,用于语义相似度检索 |
| Knowledge Base 的 Chat Model | 每次用户检索时 | 理解问题、拆分子查询、选择知识源,以及可选的答案合成 |
创建 Blob Knowledge Source 时,系统会自动生成 Data Source、Indexer、Skillset 和 Search Index。对读者来说,最关键的不是记住这些组件名字,而是理解它背后的处理逻辑:文档先被解析、分块,再补充可检索文本,最后生成向量用于召回。
截图中的 Content extraction mode = Standard 会调用 Azure Content Understanding 做更高级的文档解析与分块;如果启用了图片描述,Blob Chat Model 会参与把图片、图表等视觉信息转成文本;Embedding Model 则负责把分块内容和查询转换成向量,服务于后续的向量检索。
与 Agent 直接连接 Azure AI Search 有什么不同?
传统 RAG 通常让 Agent 直接连接一个 Search Index,配置查询类型、top_k 和过滤条件;Search 返回文档片段,再由 Agent 主模型作答。这种方式链路更短、控制更直接,适合单索引和稳定查询。
需要说明的是,Knowledge Base 并非只能被 Foundry Agent Service 调用。任何支持 Azure AI Search Knowledge Base API 的应用、Microsoft Agent Framework 或自建服务都可以调用它;Foundry Agent Service 只是提供了原生集成和托管体验。
Foundry IQ 并没有推翻 RAG,而是把越来越复杂的“检索编排”从每个 Agent 中抽离出来:
| 直接使用 Azure AI Search | 使用 Foundry IQ Knowledge Base |
|---|---|
| 通常面向一个索引 | 可统一组织多个索引型或远程知识源 |
| 通常执行一次配置好的搜索 | 可拆分问题、选择来源、并行查询和迭代检索 |
| Agent 自己处理文档并生成答案 | Knowledge Base 先重排、合并并保留引用 |
| 检索配置分散在各个 Agent 中 | 一个领域知识库可被多个 Agent 共享和独立更新 |
| 成本和延迟更容易预测 | 复杂问题效果可能更好,但会增加模型调用和延迟 |
其核心价值是关注点分离:Azure AI Search 负责检索执行,Knowledge Base 负责领域知识与检索策略,Agent 负责对话、工具调用和业务行动。按照官方公开基准,在其测试设定下,agentic retrieval 的响应质量相比传统单次 RAG 有约 36% 的提升;这个数字更适合当作方向性参考,而不是所有场景都可直接复现的通用结论。
所以它真正改变的,不只是界面入口,而是 RAG 系统里“谁来负责检索策略”这件事。
如何选择?
- 只有一个成熟索引、问题简单、强调精确控制与低延迟:继续直接使用 Azure AI Search 的索引接入或工具接入方式。
- 需要跨来源回答复合问题、理解对话上下文,或让多个 Agent 共享同一领域知识:优先考虑 Foundry IQ。
最终可以这样理解:
Foundry IQ 不是另一个搜索引擎,而是以 Azure AI Search 为基础、面向 Agent 的知识与上下文工程层。
You can outsource your thinking, but you cannot outsource your understanding.
参考资料
- Microsoft Learn:What is Foundry IQ?
- Microsoft Learn:Create a knowledge base in Azure AI Search
- Microsoft Learn:Agentic retrieval in Azure AI Search
- Microsoft Learn:Connect a Foundry IQ knowledge base to Foundry Agent Service
- Microsoft Learn:Set the retrieval reasoning effort
- Microsoft Learn:Connect an Azure AI Search index to Foundry agents
- Microsoft Learn:Agentic retrieval limits
- Microsoft Tech Community:Foundry IQ: Boost response relevance by 36% with agentic retrieval
- Microsoft Learn:Foundry IQ FAQ