最近在和产品经理以及研发团队讨论功能设计的时候,经常会遇到一个有趣的现象:在一个平台级产品中,尝试增加一个功能的时候,大家总会希望讨论,要不要把这个功能做成一个通用模块,以后在有类似需求的时候都可以复用。想法是好的,不过一旦要考虑复用,那么迎来的将是一系列的讨论,如何复用,复用的交互,其他各个模块的使用场景等等。这样一个可能简单的功能,往往要拖很久,因为考虑复用而增加很多“设计”。这些设计这不仅让我们思考,这样的复用真的让系统简单了吗?复用的目的是什么呢?是什么增加了系统的复杂度?
软件设计中有一种方法是“领域驱动设计”(Domain Driven Development),其中有一个思想是,系统复杂度的增加主要是因为领域之间的链接个数增加而导致的,并不是领域个数多少。如下图,5个元素但是有10条链接。如果只是5个彼此无关的元素,那么这个系统并不复杂。因为无需考虑彼此之间的关系。这也是面向对象思想一直希望追求的目标——高内聚低耦合。
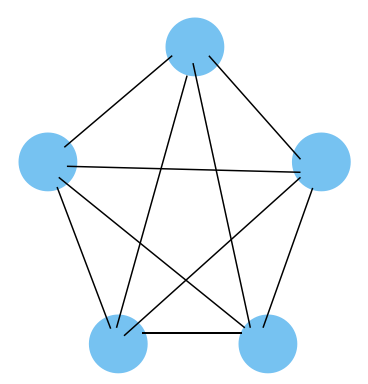
DDD中提倡在动手开发之前,先识别领域边界,每个边界内部的设计都希望是高内聚的。这样可以减少边界之间的链接,因为当出现业务改动的时候,领域对象必须要考虑和自己有联系的对象的影响。当这些链接越来越多的时候,系统自然复杂性就增加了。这里就有一个反直觉的地方。我们在设计的时候,往往会想着把功能做成通用的,这样可以最大化的利用已有模块,一个地方修改,其他所有地方重用,减少重复的工作。理想是美好的,现实是残酷的。复用自然就会增加链接,因为复用的目的就是让更多的地方能够直接使用。这就直接增加了系统的复杂度。当领域边界识别不清楚的时候,这种复用会因为不同业务的需要,导致修改这个复用组件,久而久之这个组件内部也会充斥着各种业务条件,越来越高耦合了。
回到今天的话题,如果一个功能在设计之初,最简单的方式是不考虑复用,很容易在自己的模块中设计实现,一旦其他模块有类似需求,可以先在自己内部重新实现该功能,哪怕只是代码层面的copy。如果一定需要抽取一个独立模块用于复用,那么必须要确定识别足够清晰的领域边界之后才行。否则尽量不要复用,这种反到增加了系统整体的复杂度。
践行敏捷实践,让工作去繁从简。欢迎关注我的公众号,交流落地经验。